Impressive Advancements in AI: Google Brain's Imagen vs. Dall-E 2
Written on
Introduction to Imagen
If you were impressed by Dall-E 2's capabilities, wait until you see what Google Brain has unveiled with their new model, Imagen. While Dall-E 2 has its strengths, it often falls short in achieving realism. The developers at Google Brain have focused on enhancing this aspect with Imagen. Their project page showcases numerous results and introduces a benchmarking system designed to compare various text-to-image models. According to these benchmarks, Imagen significantly outperforms Dall-E 2 and earlier image generation technologies. Check out the results in the video below!
Benchmarking Text-to-Image Models
The introduction of this benchmarking method is exciting, especially as the number of text-to-image models continues to grow, making comparison increasingly challenging. Typically, we might assume that results are not up to par, but both Imagen and Dall-E 2 defy this assumption.
In summary, Imagen is a new text-to-image model that demonstrates greater realism than Dall-E 2, as confirmed by human testers.

Understanding Text and Image Generation
Similar to Dall-E, Imagen can interpret text prompts such as “A golden retriever dog wearing a blue checkered beret and a red dotted turtleneck” and generate photorealistic images based on these descriptions. The key distinction is that Imagen not only comprehends the text but also produces images that are more realistic than those generated by previous models.
When we say that it "understands," we imply a different kind of comprehension than human understanding. The model doesn’t genuinely grasp the text or the images it creates; instead, it has learned how to represent specific phrases and objects through pixel arrangements. Nevertheless, the results often give the impression that it fully comprehends the inputs!

Creativity in Image Generation
While you can challenge the model with bizarre prompts that might not yield realistic images, it occasionally surpasses expectations and produces remarkable visuals.
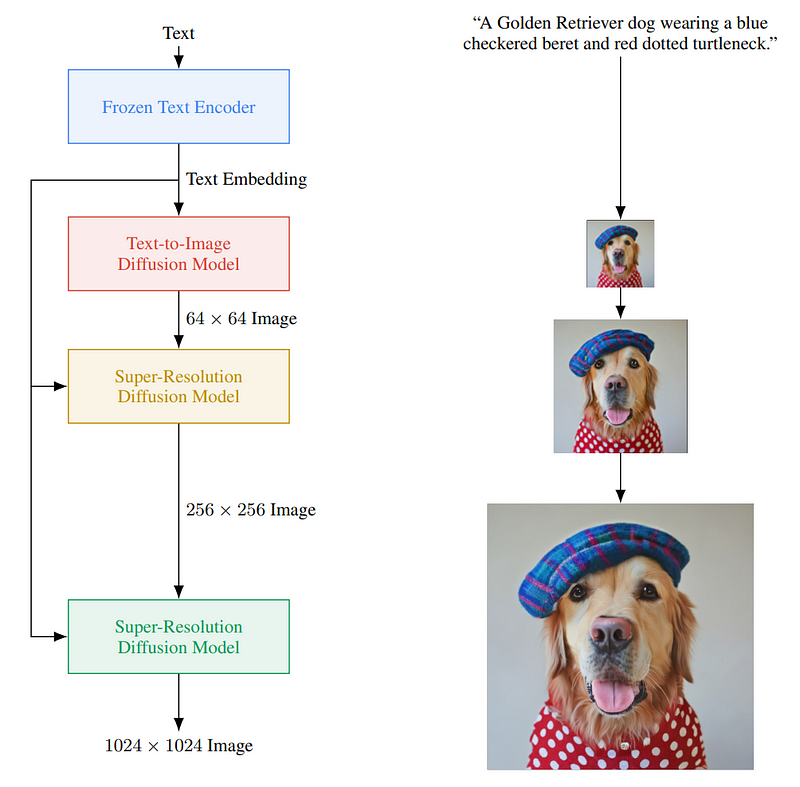
The Mechanics Behind Imagen
What sets Imagen apart is its use of a diffusion model, a topic I haven't covered before. Before utilizing the diffusion model, the system must comprehend the text input. This is a critical difference from Dall-E; Imagen employs a large pre-trained text model, akin to GPT-3, to best interpret the input. Instead of training a text model alongside the image generator, they keep the text model frozen during the image generation training phase. This approach yields significantly improved outcomes, enhancing the model's textual comprehension.
This text understanding is represented through encodings, developed from extensive datasets, allowing the model to transform text inputs into a comprehensible information space. The next step involves using these transformed text data to create images, which is where the diffusion model comes into play.
What Is a Diffusion Model?
Diffusion models are generative frameworks that convert random Gaussian noise into images by learning to reverse this noise progressively. They excel in super-resolution tasks and other image translation applications. In this case, a modified U-Net architecture is utilized, which I have discussed in previous videos.
Essentially, the model is trained to denoise images from pure noise, guided by the text encodings and a technique known as Classifier-free guidance, which is vital for the quality of the output, as detailed in their research paper.
Now, we have a model capable of taking random Gaussian noise and text encodings to denoise and generate images. However, as illustrated in the model figure, the process is more complex than it appears. The initially generated image is small; creating a larger image requires significantly more computation and a larger model, which may not be feasible. Instead, they first produce a photorealistic image with the diffusion model and then iteratively enhance the image quality using additional diffusion models.

Refining the Generated Images
To improve the generated image's resolution, the process involves initially corrupting this low-resolution output with Gaussian noise and training a secondary diffusion model to enhance the modified image.
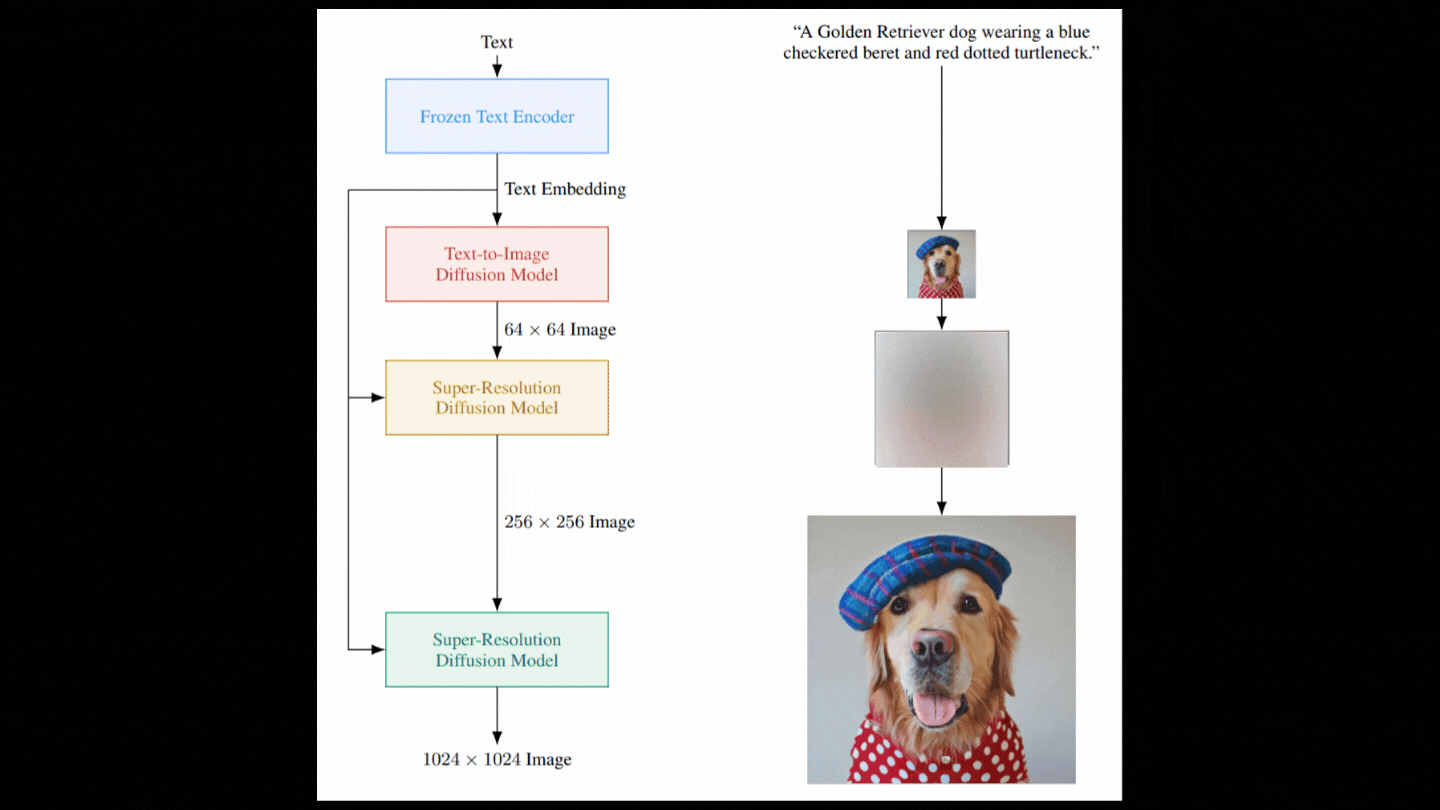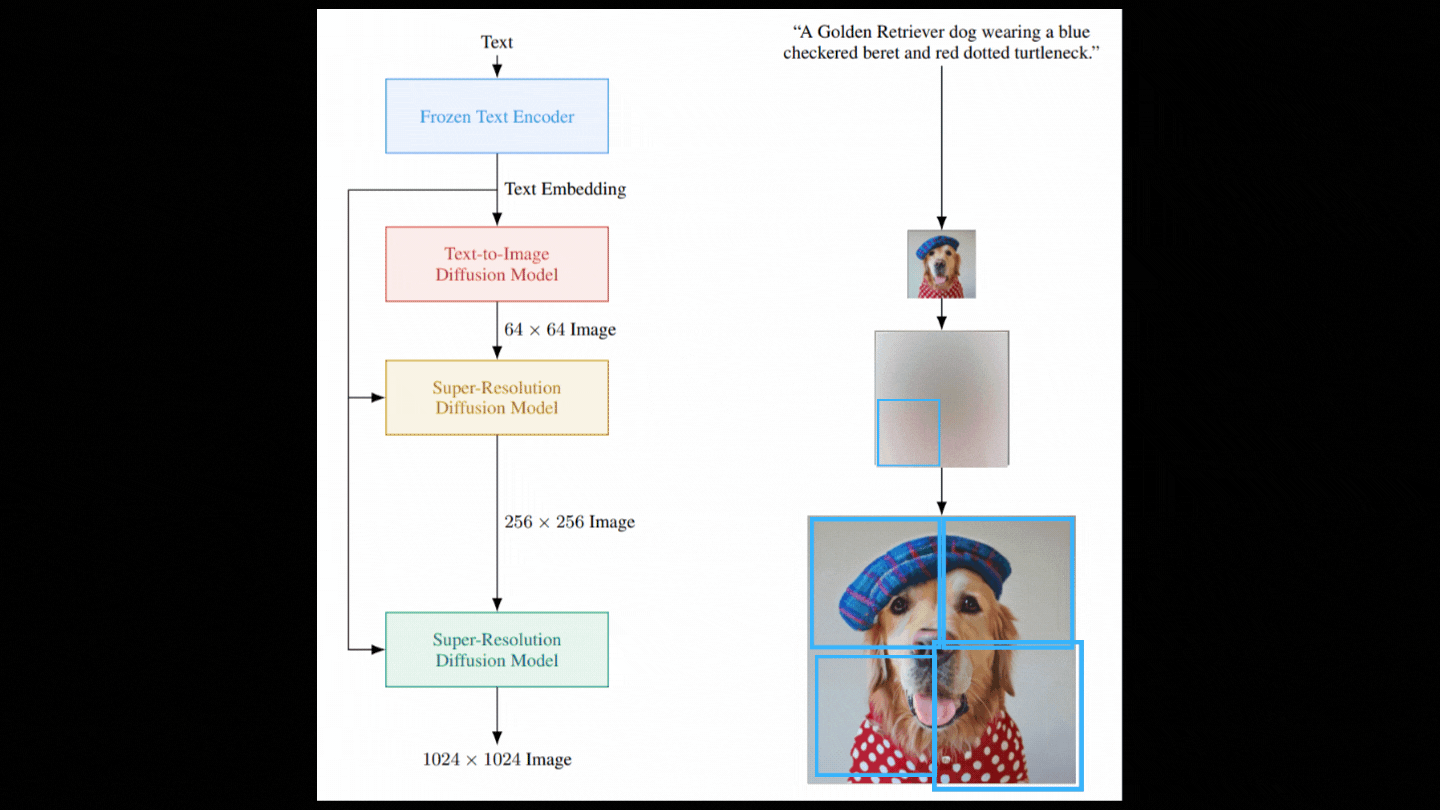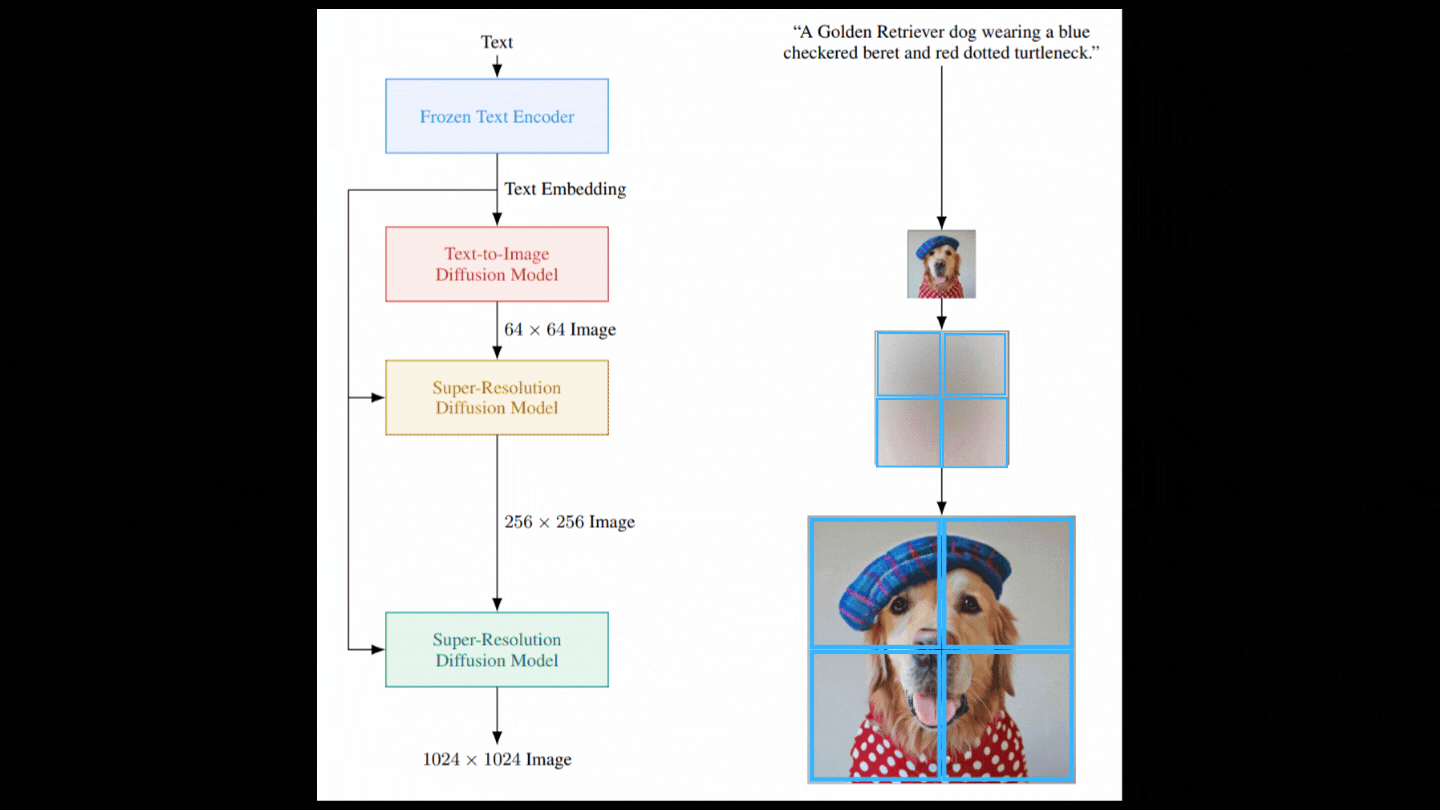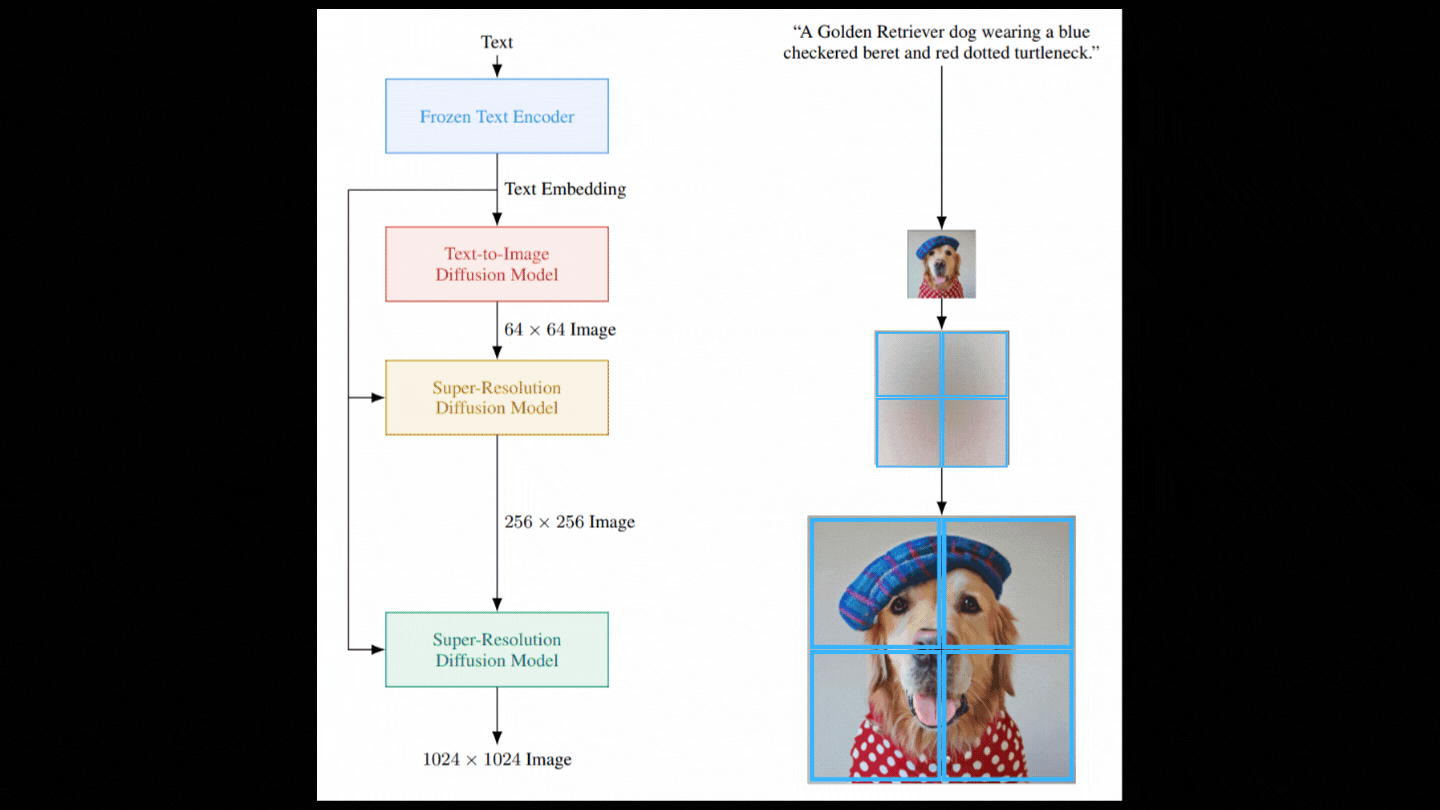
This two-step process is repeated with another model, using patches of the image to maintain computational efficiency. Ultimately, this results in high-resolution, photorealistic images.

Conclusion and Future Thoughts
This overview highlights the impressive capabilities of Imagen, which produces stunning results. I encourage you to explore their detailed research paper for a comprehensive understanding of their methodology and results analysis.
What are your thoughts? Do you find Imagen's results to be on par with or superior to Dall-E 2? I believe it stands as a formidable competitor to Dall-E at this time. Share your insights regarding this exciting development from Google Brain.
Thank you for reading! If you found this article helpful, please consider liking the video and subscribing to the blog for more updates on innovative AI news. I'll see you next week with another fascinating paper!