Unlocking the Future of Voice Recognition: The AI Revolution
Written on
Chapter 1: The Evolution of Voice Recognition Technology
Imagine having the capability to recognize someone solely by their voice, regardless of the surrounding noise or environment. This is the thrilling frontier of speaker recognition technology. Researchers have introduced an innovative framework that effectively separates speaker information from ambient sounds, enabling AI to accurately identify voices in various settings. By employing an auto-encoder, this technology isolates the unique characteristics of a speaker's voice from disruptive background noise.
This advancement is transformative, making AI speaker recognition dependable even in chaotic environments like bustling streets or crowded cafes. It's akin to possessing a superpower, allowing you to identify your friends by their voice at a loud gathering. The team's framework not only boosts the precision of speaker recognition but also ensures compatibility with existing systems. This translates to more dependable voice assistants and security measures that function effectively in any context.
The first video showcases a remarkable AI project focused on speaker identification, revealing how such technologies can revolutionize our interaction with voice recognition systems.
Section 1.1: The Significance of Accurate Speaker Recognition
In the domain of AI, the ability to accurately discern between different speakers is transformative. Conventional systems frequently falter in noisy environments, where background sounds can obscure voice signals, complicating recognition. The new framework directly addresses this challenge by utilizing an auto-encoder to eliminate environmental noise, ensuring robustness and effectiveness across diverse conditions.
Imagine attempting to identify a friend's voice in a noisy cafeteria. While traditional AI might struggle, this new methodology guarantees accurate recognition. This is particularly crucial for security applications, where precise voice identification can thwart unauthorized access. For a young user, this means enhanced voice-activated devices that operate seamlessly in varied environments, from school corridors to bustling streets.
Subsection 1.1.1: Proven Performance Improvements
The researchers conducted extensive tests on their framework, demonstrating a remarkable performance enhancement of up to 16%. This improvement signifies a practical advancement, ensuring reliable and consistent performance in real-world applications.
Chapter 2: The Mechanisms Behind the Breakthrough
The field of speaker recognition is undergoing a significant transformation, largely driven by the need to distinguish vital voice features from background noise. The newly developed framework employs an advanced auto-encoder to facilitate this separation, allowing AI systems to concentrate on the voice itself while disregarding irrelevant noise that often perplexes traditional systems.
Think of it as a pair of extraordinary headphones that enable you to hear someone distinctly, even amidst chaos. This is precisely what this new AI framework achieves. It enhances the accuracy and reliability of speaker recognition, crucial for both security and personal assistant applications. For younger audiences, this technology promises voice-activated devices that comprehend you perfectly, regardless of external noise.
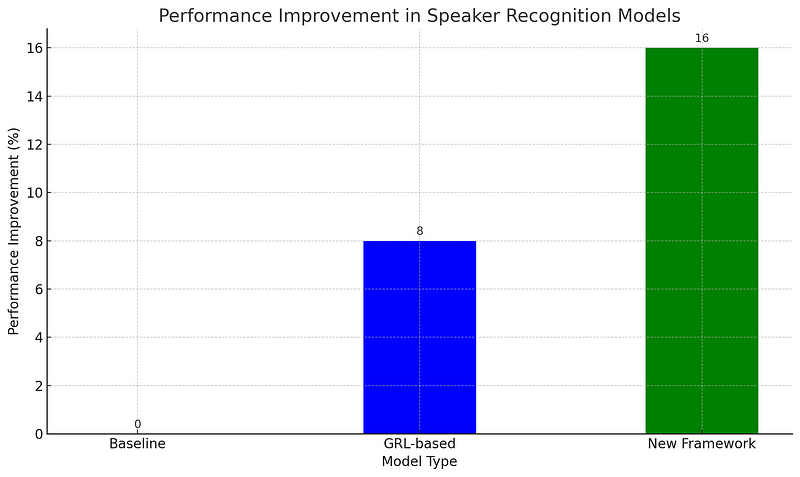
The graph illustrates the substantial performance gains achieved by the new framework in speaker recognition models, highlighting a 16% improvement over baseline systems.
Echoes of Tomorrow: The Future of Voice Recognition
As AI continues to permeate our daily lives, the capacity for precise voice recognition becomes increasingly vital. This innovative framework signifies a major leap forward in this crucial domain.
Section 2.1: Environment-Independent Recognition
The framework empowers AI systems to accurately recognize voices in any environment by segregating speaker features from background noise. This advancement enhances the reliability and versatility of AI applications.
Section 2.2: Leveraging Auto-Encoder Technology
Utilizing an auto-encoder allows the system to hone in on essential aspects of the speaker's voice while filtering out distracting environmental sounds, leading to a notable increase in recognition accuracy.
Section 2.3: Real-World Applications and Compatibility
The framework has undergone rigorous testing, revealing up to a 16% performance increase compared to conventional methods. This makes it a practical solution for various real-world scenarios. Furthermore, it is designed for seamless integration with existing speaker recognition systems, requiring minimal modifications, thus facilitating widespread adoption.
The promise of AI that can hear and comprehend us flawlessly is not a distant dream but an imminent reality, paving the way for a future where technology collaborates with us effortlessly, enriching every aspect of our lives.
The second video discusses the revolutionary impact of natural language processing and speech recognition technologies like Siri and Alexa, showcasing their evolution and future potential.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your window into the future of technology. Subscribe for insightful videos every Saturday!
Watch us on YouTube.